Python엔 eval 이 있는데 c++ 엔 왜 없는가 하면서 직접 만든 후위 표기식을 이용한 eval 구현체이다.
이제 여기에 bigint 같은 것을 끼얹으면 큰 수 연산도 손쉽게 할 수 있다.
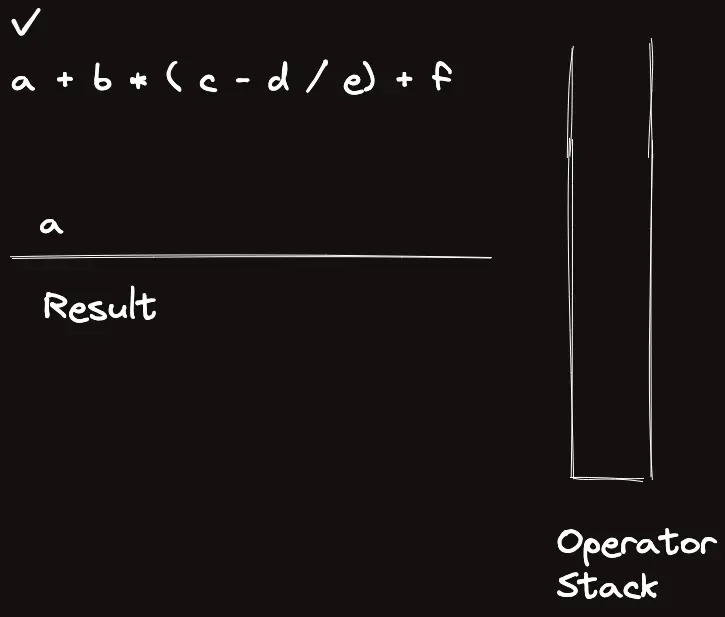
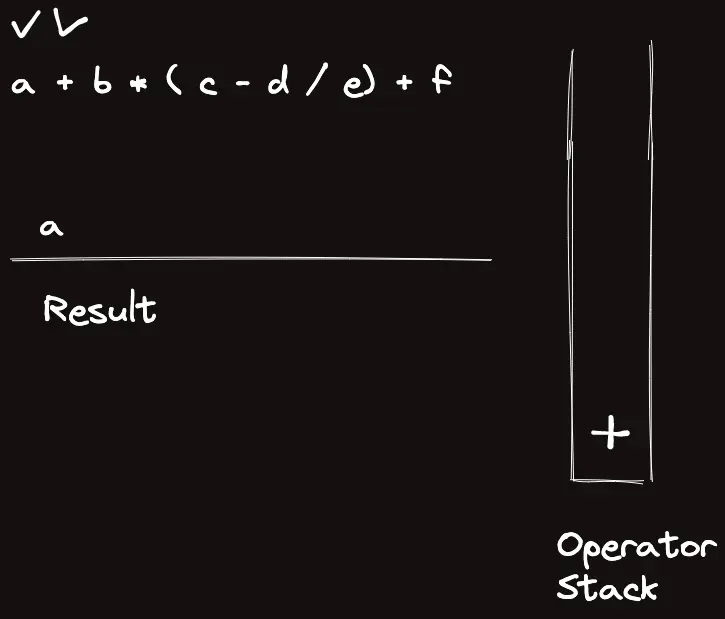
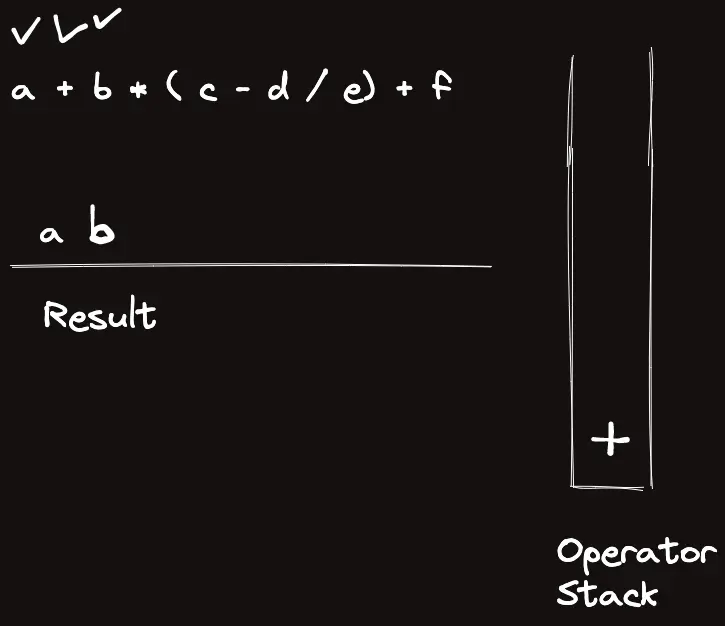
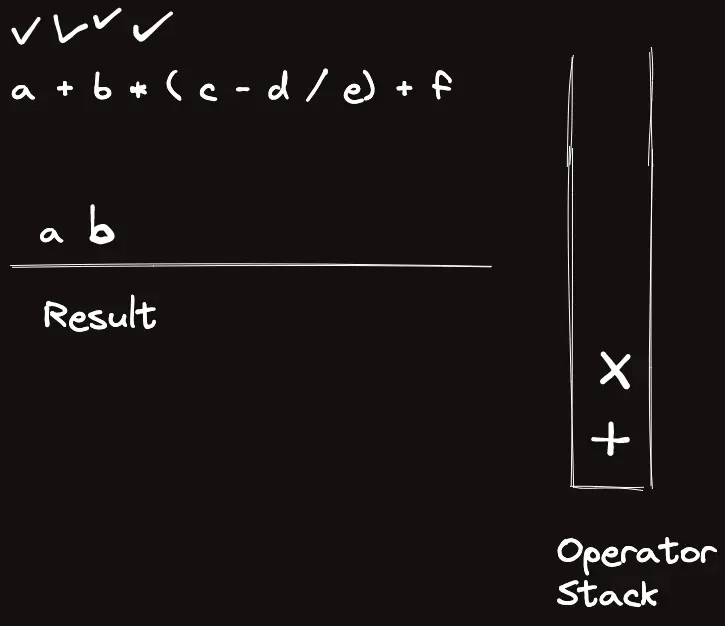
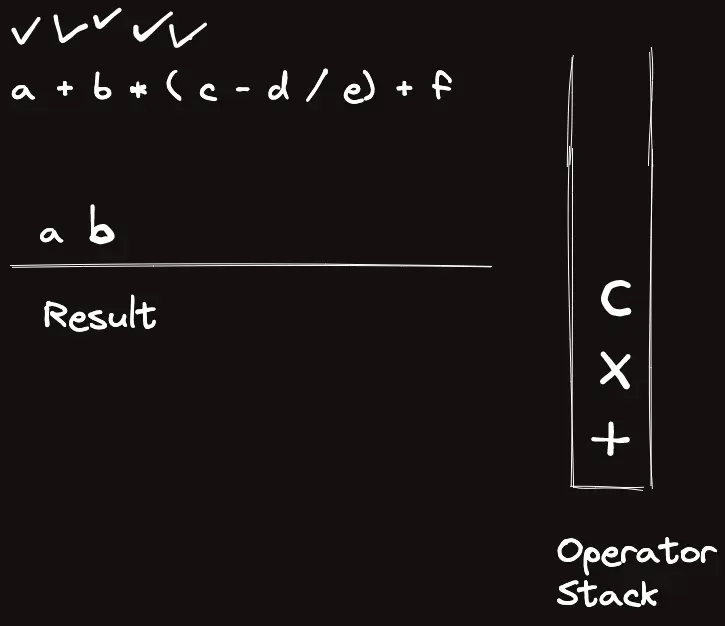
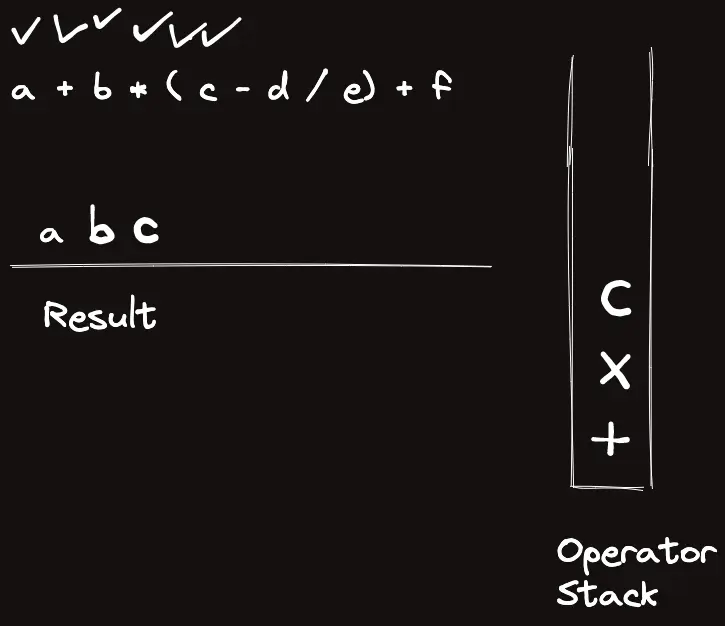
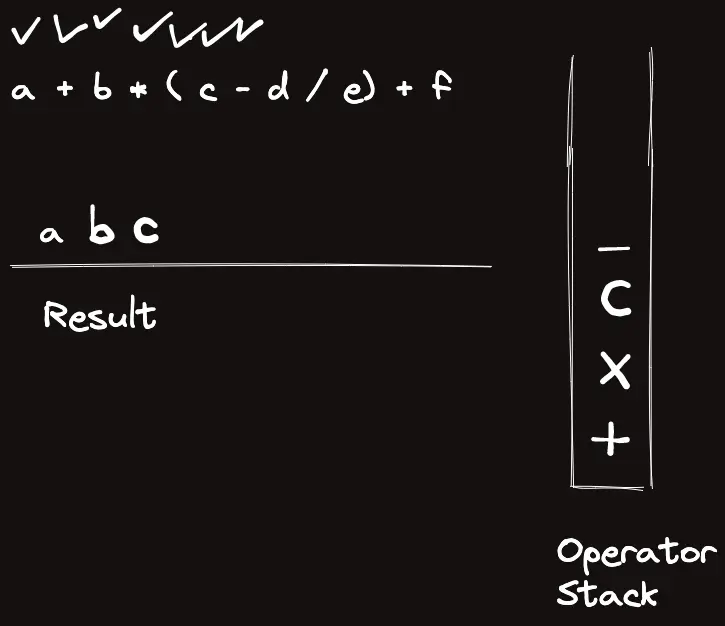
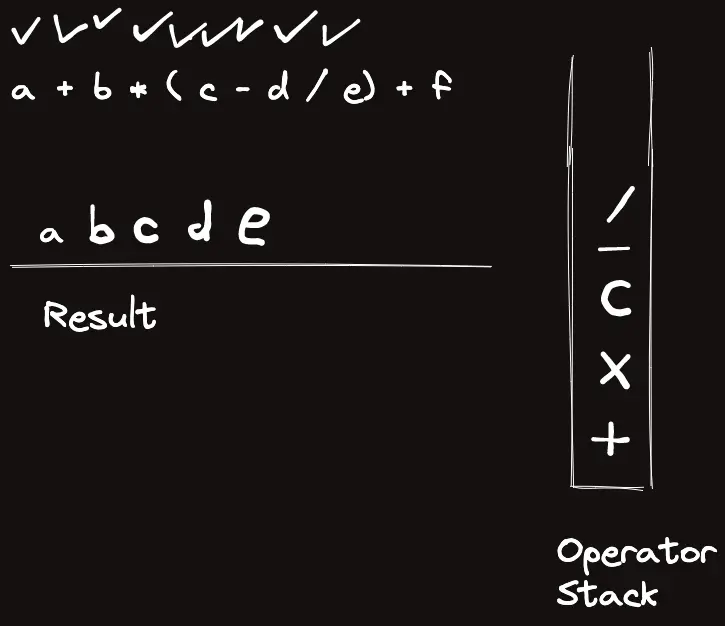
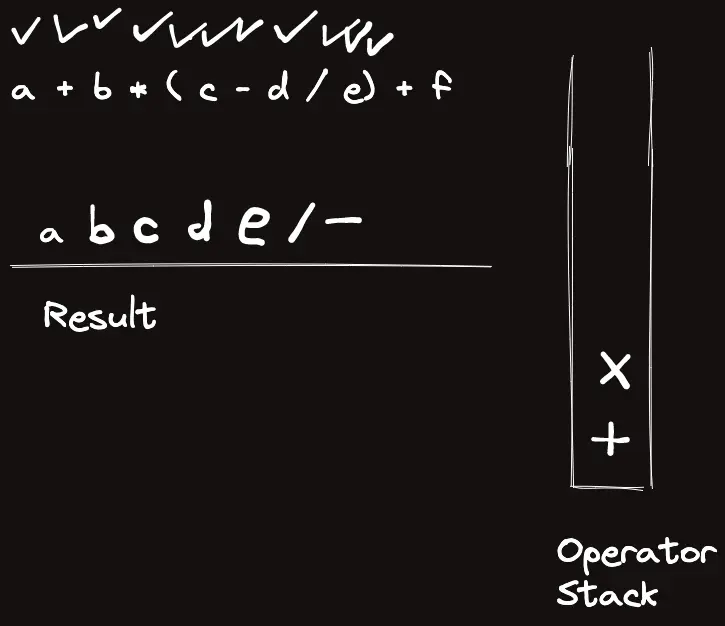
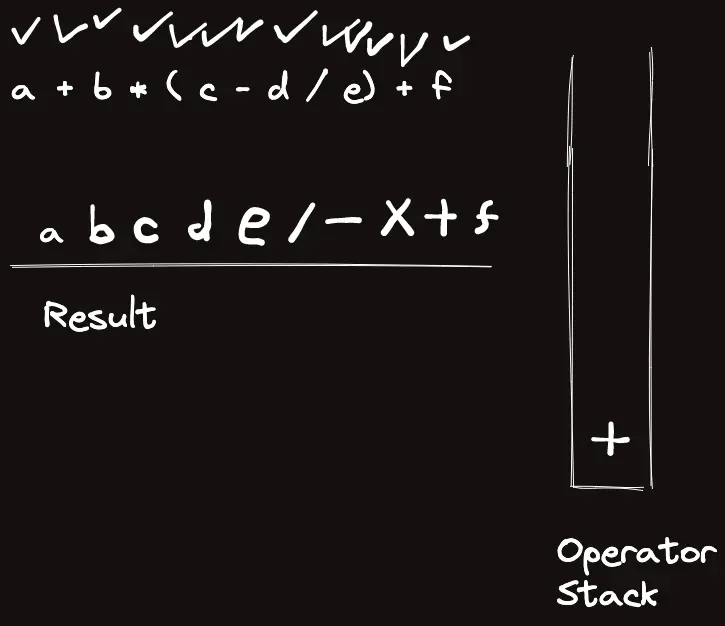
template<classT>struct_eval{stringops="+-*/%()";boolis_op(charc){returnops.find(c)!=string::npos;}boolis_op(stringc){returnsz(c)==1&&is_op(c[0]);}Trun_op(Ta,Tb,charop){if(op=='+')returna+b;elseif(op=='-')returna-b;elseif(op=='*')returna*b;elseif(op=='/')returna/b;elsereturna%b;}Trun_op(Ta,Tb,stringop){returnrun_op(a,b,op[0]);}intop_priority(stringop){if(op=="*"||op=="/"||op=="%")return3;elseif(op=="+"||op=="-")return2;elsereturn1;}Tcalc_infix(conststring&s){returncalc_postfix(to_postfix(s));}Tcalc_postfix(constvector<string>&s){vector<T>t;for(auto&c:s){if(is_op(c)){Tval=run_op(t[sz(t)-2],t[sz(t)-1],c[0]);t.pop_back(),t.pop_back(),t.push_back(val);}else{// Warning: long long conversion will cause crash on bigint usaget.push_back(stoll(c));}}returnt[0];}vector<string>to_postfix(constvector<string>&s){vector<string>ret,op;for(auto&c:s){if(is_op(c)){if(c=="(")op.push_back("(");elseif(c==")"){while(sz(op)&&op.back()!="(")ret.pb(op.back()),op.pop_back();op.pop_back();}else{while(sz(op)&&op_priority(op.back())>=op_priority(c))ret.pb(op.back()),op.pop_back();op.push_back(c);}}else{ret.pb(c);}}while(sz(op))ret.pb(op.back()),op.pop_back();returnret;}vector<string>to_postfix(conststring&s){returnto_postfix(parse(s));}vector<string>parse(conststring&s){vector<string>ret;stringtmp;for(inti=0;i<sz(s);i++){if(is_op(s[i]))ret.pb(string(1,s[i]));elseif(i==sz(s)-1||is_op(s[i+1]))ret.pb(tmp+s[i]),tmp="";elsetmp+=s[i];}if(sz(ret)&&ret[0]=="-"){// leading negative operatorret[1]="-"+ret[1];ret.erase(ret.begin());}returnret;}stringto_raw(constvector<string>&s){stringret;for(auto&c:s)ret+=c;returnret;}};_eval<ll>eval;
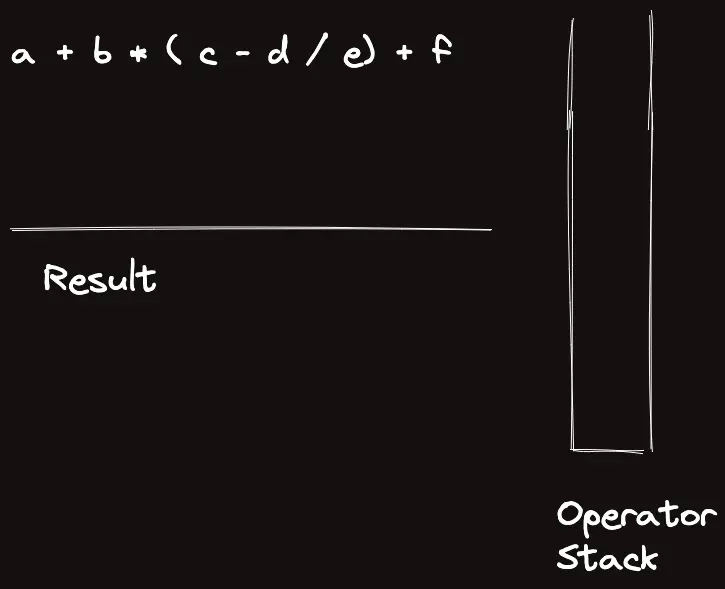
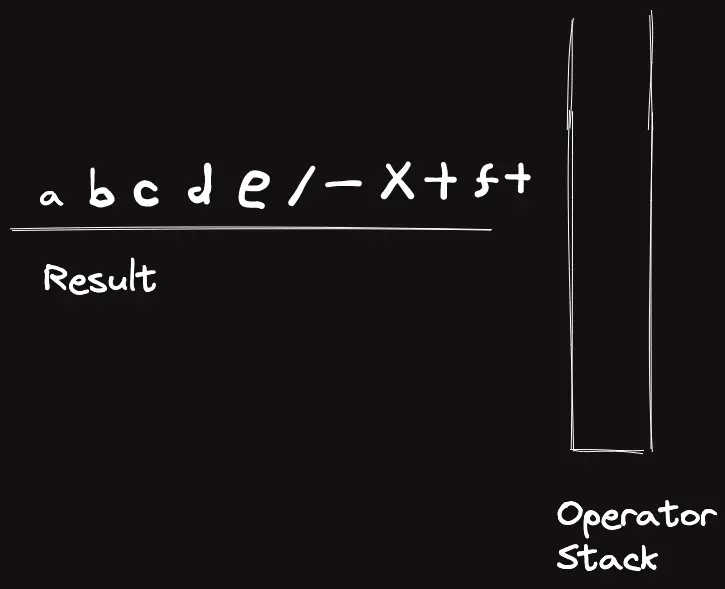


Comments