Classification의 여러 방법들, Decision Tree

ML CheatsheetPermalink
우리가 어떤 데이터를 목적에 따라 학습시키고 싶을 때 어떤 알고리즘을 사용해서 학습을 진행시켜야 할 지에 대해서 scikit-learn에서 정리한 가이드라인이다.
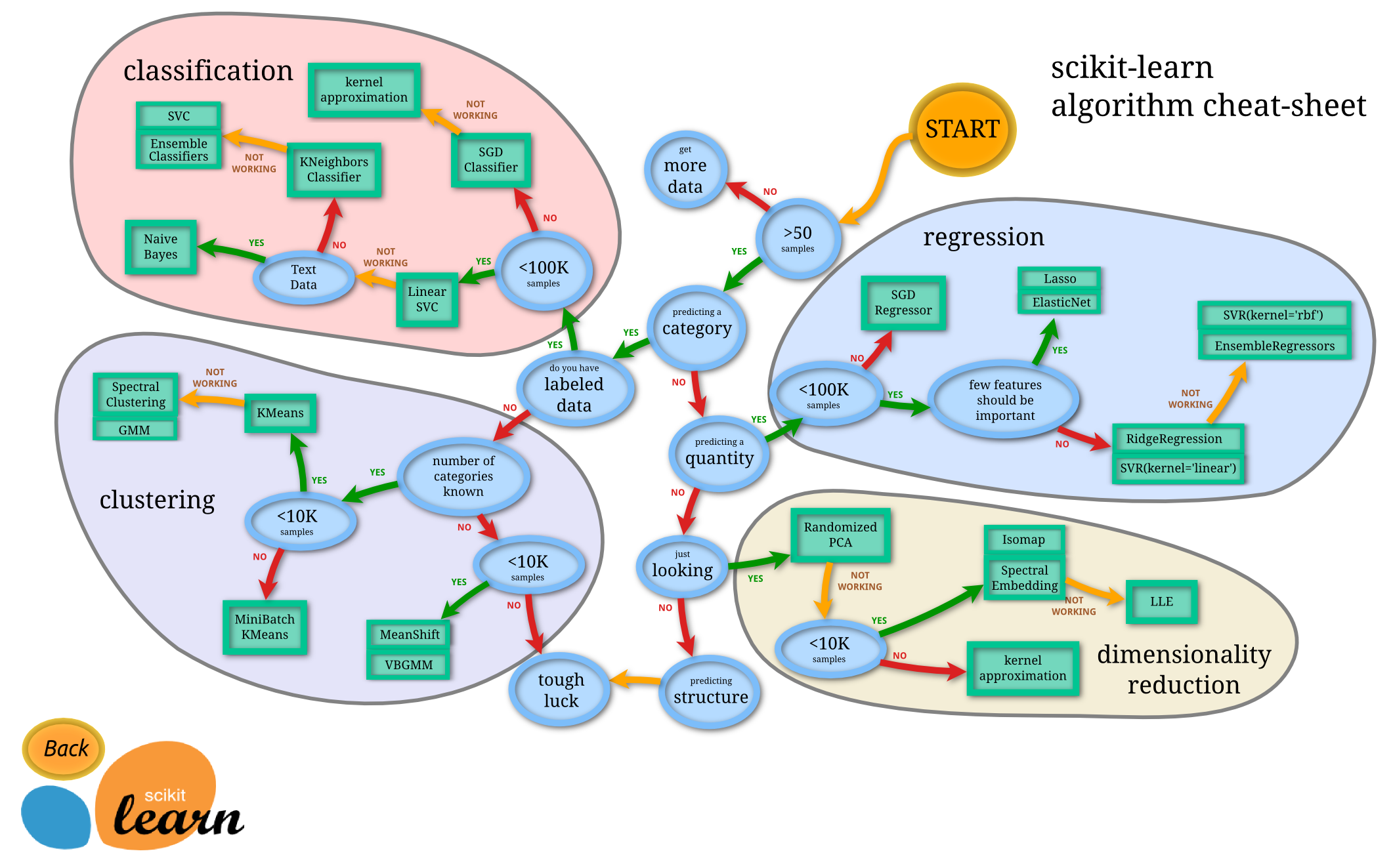
그리고 다음은 ML Cheatsheet이며 비슷한 내용이 정리되어있다.
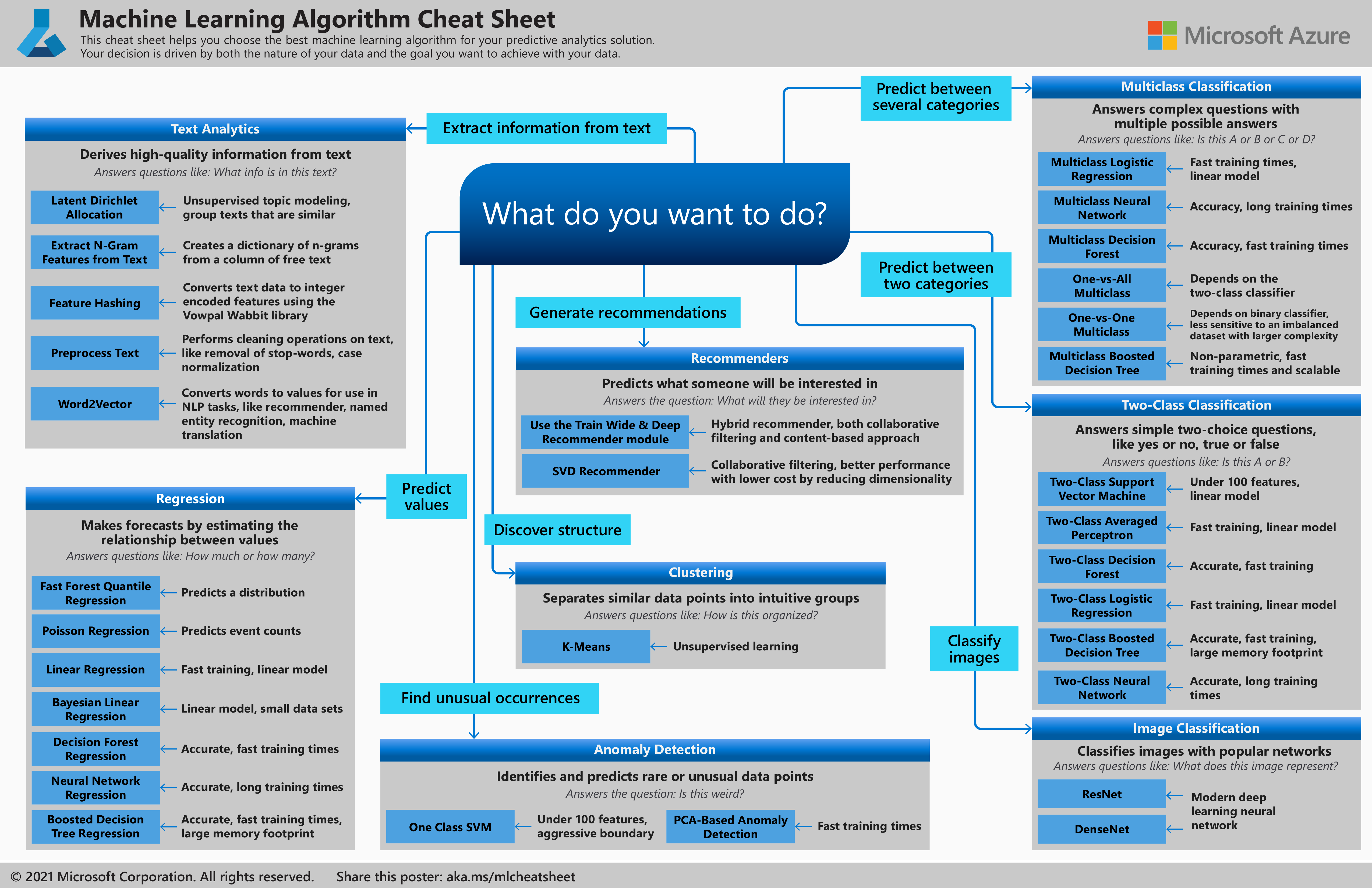
이중에서도 Classification(분류)에 대해서 어떤 기법들이 있는지 알아보자.
Classification MethodsPermalink
다음은 이진 분류와 다중 분류의 기법들이다.


Logistic RegressionPermalink
단순한 로지스틱 회귀를 의미한다.
scikit learn에 LogisticRegression 으로 구현되어 있다.
이름과 다르게 Classification을 위한 구현체이다.
Support Vector Machine(SVM)Permalink
가장 많이 쓰이는 고성능 모델이다.
HyperPlain을 찾아 클래스간 마진을 최대로 하여 서포트 벡터라 부르는 일부 샘플을 사용해 분류를한다.
이 때, 커널(Kernal)을 이용해 원래 선형 분리가 안되는 데이터를 고차원으로 옮겨서 선형 분리가 가능하게 만들 수 있다.
단순한 코드 예시는 다음과 같다.
from sklearn.svm import SVC
svc = SVC(kernel='rbf', C=1.0, gamma='scale')
SVC는 Support Vector Classification의 약자이다.
SVM의 장점은 Versatile(다재다능)하다는 것이다.
커널을 어떤것을 사용하느냐에 따라 데이터에 따른 분류 과정을 이것저것에 잘 최적화를 시킬 수 있다.
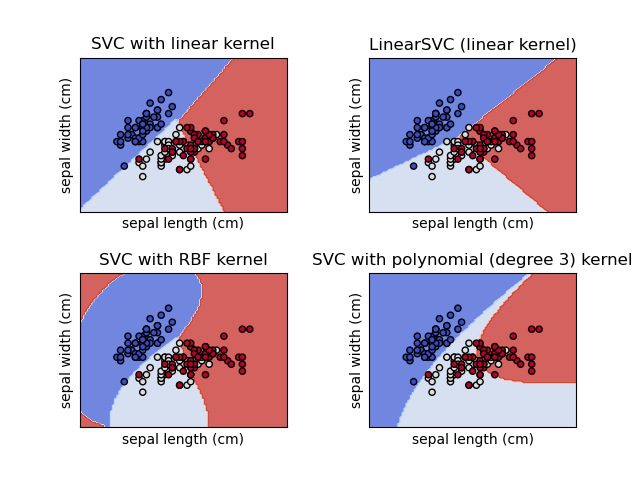
선형 SVM(Linear Kernal)은 말처럼 Classificaiton이 선형으로 이루어져있다.
하지만 SVC의 기본 커널인 RBF 를 보면 직선이 아닌 곡선으로 분류가 되는것을 알 수 있는데, 이건 저차원을 고차원으로 변경시키는 커널 함수의 역할이다.
Decision TreesPermalink
Decision Trees(의사 결정 트리)는 non-parametric supervised learning method이다.
non-parametric이란 것은 모델이 고정된 인자를 가지지 않는다는 의미이며 트리의 분류 알고리즘이 feature들의 분석과 결과따라 자유롭게 구성된다는 의미이다.
Decision Tree는 Classificaiton과 Regression모두에 사용될 수 있다.
Decision Tree는 단순하게 노드들이 계속해서 feature별로 쪼갰을 때, information gain이 높은 feature를 선택해 그거 기준으로 쪼개나가는 과정이다.
information gain은 분할 후 정보 이득이다.
각 노드에 있는 샘플들을 특정 feature별로 분류했을 때 불순한 정도를 Impurity(불순도)라고 하는데, 해당 노드 안에 서로 다른 데이터가 얼마나 섞여있는지에 대한 수치이다.
이 불순도를 계산하는 방법은 Decision Tree가 Classification이냐 Regression이냐에 따라 다른데, Classification의 경우 Gini Index(지니 지수)와 Entropy(엔트로피)를 주로 사용하고 Regression의 경우 Variance(MSE, 분산)을 사용한다.
Gini Index - Classification ImpurityPermalink
값이 작을수록 순수하고 는 클래스 의 비율이다. 예를 들어 공이 개 있고 노란공이 개, 파란공이 개 있다면 이고, 이다.
Entropy - Classification ImpurityPermalink
마찬가지로 값이 작을수록 순수하다.
Variance - Regression ImpurityPermalink
는 평균을 의미하고 는 번째 샘플의 정답 값(타겟 값)을 의미한다.
마찬가지로 작을수록 좋은 분할이다.
각 Impurity 계산은 criterion 인자로 지정할 수 있다.
DecisionTreeClassifier(criterion='gini') # 기본값
DecisionTreeClassifier(criterion='entropy') # 엔트로피
DecisionTreeRegressor(criterion='squared_error') # 회귀 분산
Decision Tree에서 분류 과정Permalink
루트 노드부터 시작해서 각 Feature 별로 Impurity를 계산해서 가장 Information Gain이 높은(Impurity가 가장 낮아지는) Feature 로 분류를 한다.
한 번 썼던 Feature는 다시 쓸 수 없는가? => 아니다. 특정 Feature가 Feature < 100 으로 쓰였다면 자식 노드에서 또 Feature < 50 으로 쓰일 수 있다.
하지만 범주형 Feature라면 이미 동일한 값들만 존재할 것이기 때문에 다시 쓰는게 의미없다.
그렇게 계속 분류를 하다가 종료 조건이 달성되면 분류를 그만한다.
그러면 leaf node에는 여러 샘플이 있을 것이고 분류나 회귀에서 그 leaf node까지 타고들어가면 어떤 결론을 내야할지 궁금할 것이다.
분류같은 경우 가장 많은 클래스(다수 클래스)가 그 노드의 예측이 되고 회귀같은 경우 보통 값의 평균이 그 노드의 예측이 된다.
Decision Tree의 과적합 해소방법들Permalink
트리를 너무 세세하게 분류하면 Full tree(최대 트리)가 되어 과적합이 생길수있기 때문에 여러가지 기법을 이용해 과적합을 방지한다.
- Pruning: 가지치기를 통해 일부 sub tree를 완전히 제거하여 과적합을 방지한다.
- Max Depth: 트리의 최대 높이를 제한한다.
- Min/Max samples Leaf: Leaf node의 최소/최대 샘플 수 제한
- 등등
Pruning 시에 다음과 같은 비용을 최소화하도록 학습된다.
- : Leaf Node의 수, 구조의 복잡도와 비례
- : 검증데이터에 대한 오차
- : 하이퍼 파라미터, 보통
그러니까, 트리가 복잡해지면 Cost가 올라가고 오차율이 올라가면 Cost가 올라가기 때문에 그 밸런스를 찾는 과정이라고 이해할 수 있다.
Scikit Learn에서의 사용Permalink
scikit-learn에서의 사용법은 DecisionTreeClassifier와 DecisionTreeRegressor 클래스를 이용하는 것이다.
다음은 예시 코드이다.
from sklearn.datasets import make_classification, make_regression
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor, plot_tree
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
# 분류용 데이터 생성
X_cls, y_cls = make_classification(n_samples=100, n_features=4, random_state=0)
Xc_train, Xc_test, yc_train, yc_test = train_test_split(X_cls, y_cls, test_size=0.3, random_state=42)
# 회귀용 데이터 생성
X_reg, y_reg = make_regression(n_samples=100, n_features=1, noise=10, random_state=0)
Xr_train, Xr_test, yr_train, yr_test = train_test_split(X_reg, y_reg, test_size=0.3, random_state=42)
# 분류 모델
clf = DecisionTreeClassifier(
criterion='entropy', # 분할 기준 (gini / entropy)
max_depth=3, # 최대 트리 깊이
min_samples_split=4, # 내부 노드 분할 최소 샘플 수
min_samples_leaf=2, # 리프 노드 최소 샘플 수
random_state=0
)
clf.fit(Xc_train, yc_train)
# 회귀 모델
reg = DecisionTreeRegressor(
criterion='squared_error', # 손실 기준
max_depth=3,
min_samples_split=4,
min_samples_leaf=2,
random_state=0
)
reg.fit(Xr_train, yr_train)
# 시각화
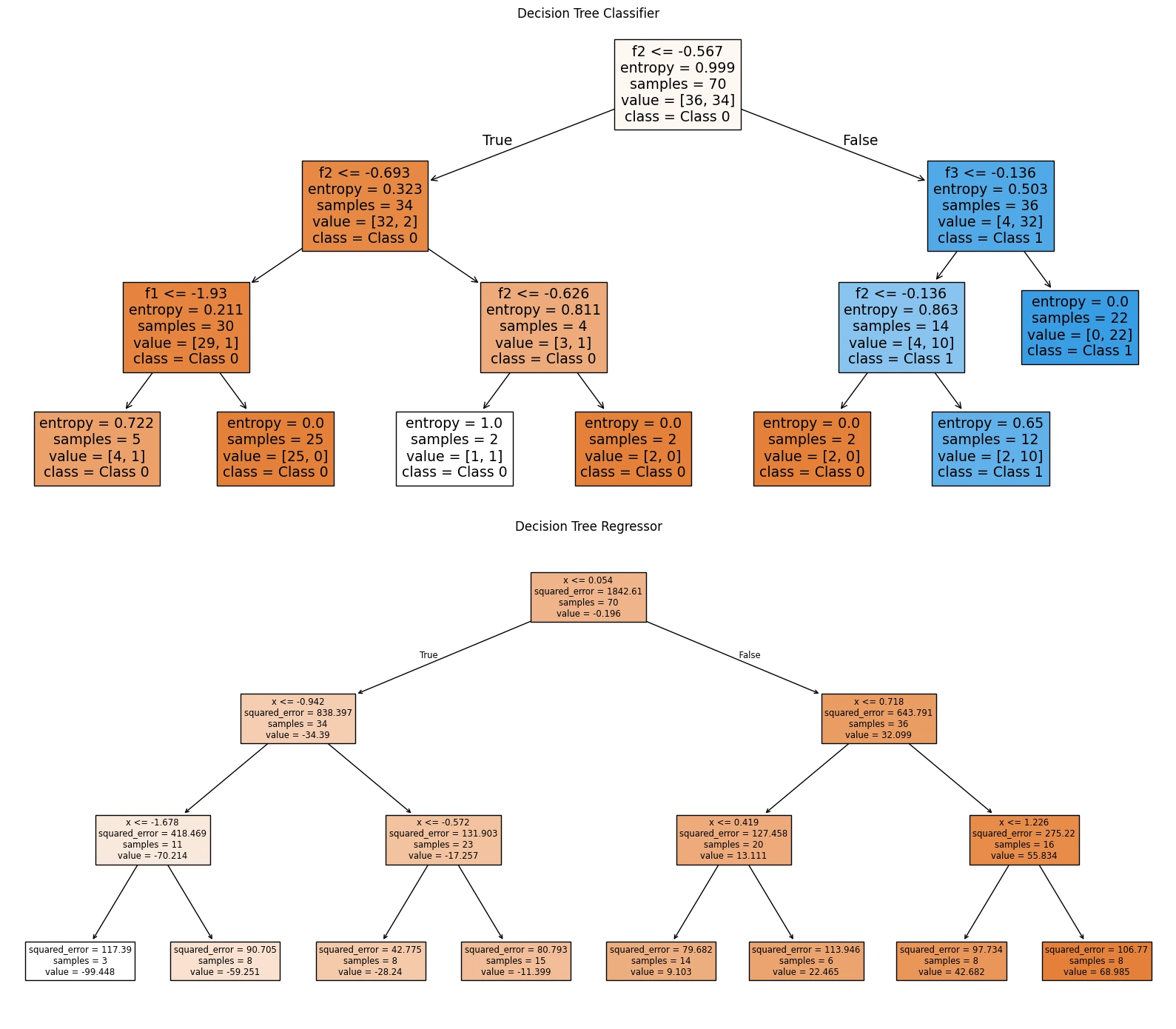
fig, axs = plt.subplots(1, 2, figsize=(16, 6))
# 분류 트리 시각화
plot_tree(clf, feature_names=[f"f{i}" for i in range(X_cls.shape[1])],
class_names=['Class 0', 'Class 1'], filled=True, ax=axs[0])
axs[0].set_title("Decision Tree Classifier")
# 회귀 트리 시각화
plot_tree(reg, feature_names=["x"], filled=True, ax=axs[1])
axs[1].set_title("Decision Tree Regressor")
plt.tight_layout()
plt.show()
sklearn.tree의 DecisionTreeClassifier, DecisionTreeRegressor를 이용해 모델을 학습시킬 수 있고, plot_tree를 이용해 트리를 그릴 수 있다.
ReferencesPermalink
- https://wooono.tistory.com/104


Comments