머신러닝에 쓰이는 라이브러리들

LibrariesPermalink
머신러닝에 쓰는 라이브러리들은 주로 다음과 같다.
matplotlibPermalink
데이터 시각화 라이브러리이며 특히 pyplot을 이용해 편하게 데이터를 시각화할 수 있다. seaborn 도 이것을 이용해 만들어졌다.
보통 다음과 같이 선언하여 쓴다.
import matplotlib.pyplot as plt
numpyPermalink
대표적인 데이터처리 라이브러리이며 수치 계산이나 행렬 연산에 최적화가 되어있다. 특히 수학 과학연산 등에 많이 활용되며 ndarray 라는 배열을 다루는 라이브러리이다.
import numpy as np
pandasPermalink
DataFrame, Series 라는 데이터 구조가 주가 되는 데이터 처리 라이브러리이며 csv에서 파일을 읽어서 전처리를 하거나 데이터 분석, 가공등에 특화된 라이브러리이다.
import pandas as pd
scikit-learnPermalink
주로 전통적인 머신러닝에 사용되는 모델들을 쉽게 쓸 수 있는 라이브러리이다. 회귀, 분류, 의사결정트리, 랜덤포레스트, SVM 등을 가져다 쓸 수 있어 널리 활용된다.
라이브러리들을 쓰는 예시Permalink
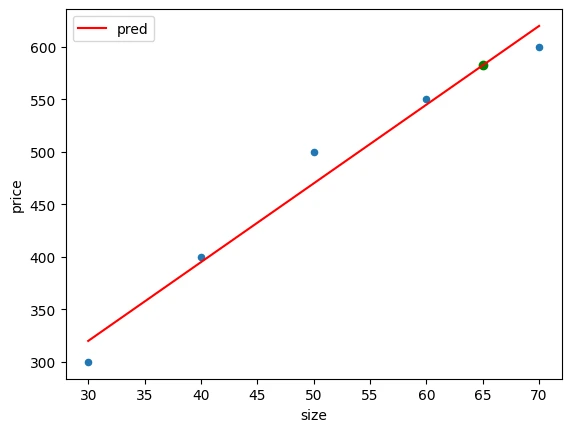
이런것들을 다함께 쓰면 이런식으로 코드를 짤 수 있다. 집값을 예측하는 단순한 선형 회귀 모델을 학습시키고 시각화하는 코드이다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 데이터프레임 생성
df = pd.DataFrame({
'size': [30, 40, 50, 60, 70],
'price': [300, 400, 500, 550, 600]
})
# 모델 학습
model = LinearRegression().fit(df[['size']], df['price'])
# 예측
size_new = 65
price_pred = model.predict([[size_new]])[0]
print(f'{size_new}평 예상 가격: {price_pred:.0f}만원')
# 시각화
ax = df.plot.scatter(x='size', y='price')
df['pred'] = model.predict(df[['size']])
df.plot(x='size', y='pred', ax=ax, color='red')
plt.scatter(size_new, price_pred, color='green')
plt.show()



Comments